Data Driven AI with #fastmemory
Tera-Flop AI: Scaling Beyond the RAG Bottleneck
We recently released the Enterprise-Ready, Open-Source FastMemory engine—a lightweight, ultra-efficient cognitive architecture designed to replace heavy, hallucination-prone RAG systems. This issue focuses on how that engine scales across the global cloud ecosystem.
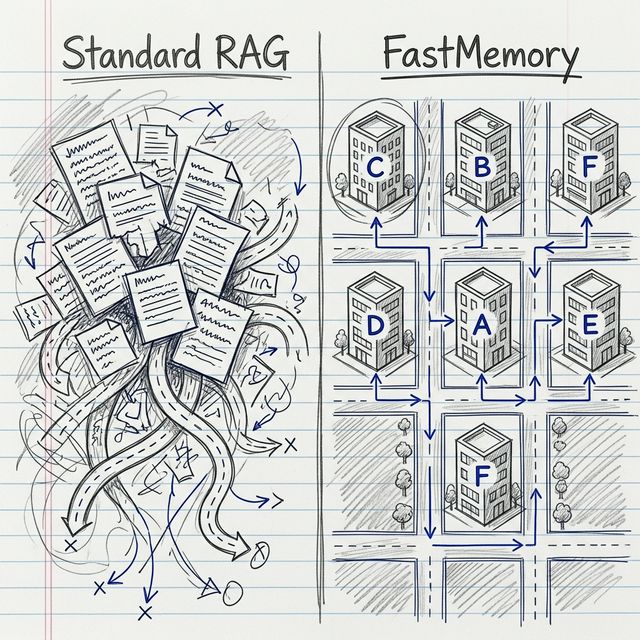
The race to build production-scale AI agents is hitting a wall. Developers are drowning in the complexity of vector re-indexing, manual graph syncs, and the constant threat of RAG hallucinations.
At FastBuilder.AI, we believe compute should be spent on reasoning, not management. That's why we've finalized our Cloud Ecosystem Native integration—enabling you to deploy FastMemory directly across AWS, Azure, and GCP.
Ditch the "Pile of Snippets." Build agents that navigate Exa-Flop data structures with zero ontology management overhead.
☁️ Your Cloud, Your Memory
We've launched 13 modular deployment templates and Python examples that bridge the gap between your data lake and your agent's brain:
- AWS Integration: Use AWS Glue and S3 as a persistent, high-speed knowledge source.
- Azure Ecosystem: Seamlessly bind to Azure Data Factory and SQL for enterprise-grade RBAC.
- GCP Native: Extract relationship graphs directly from BigQuery with millisecond latency.
🛠️ Technical Deep Dive: The Cognitive Schema
FastMemory builds intelligence by transforming raw text into a deterministic CBFDAE (Component, Block, Function, Data, Access, Event) graph. This happens at the data layer—ensuring your AI has a "ground truth" before it ever executes a query.
# Healthcare Cognitive Schema (Patient Portal)
{
"Component": "C_Patient_Portal",
"Block": "B_Clinical_Workflow",
"Function": "F_Appointment_Booking",
"Data": "D_Doctor_Calendar",
"Access": "Role_HIPAA_Compliance_Admin",
"Event": "E_Patient_Notification"
}
By mapping Access (A_) nodes to specific roles and Events (E_) to triggers, your AI agent gains a deterministic understanding of the rules governing the data. This eliminates the "hallucination gap" inherent in standard vector databases.
☁️ Scaling the Engine: Cloud Templates
Once your memory graph is structured, it can be deployed at scale across any enterprise environment. Our new Cloud Templates provide a "pave the way" architecture for hosting the FastMemory engine on your preferred provider:
- AWS Deployment: ECS Fargate + Amazon Neptune (Graph Service).
- Azure Deployment: Azure Container Instances + CosmosDB.
- GCP Deployment: GKE Microservices + Neo4j on Compute Engine.
Explore the full deployment code for all three major providers over at our Cloud Templates Hub.
⚡ Performance That Scales
FastMemory delivers a 30x delta update speed over traditional vector updates. By focusing on functional clustering rather than raw semantic proximity, we achieve:
This isn't just about speed—it's about reliability. When your agent queries FastMemory on Azure or AWS, it retrieves the entire Cognitive Block (CBFDAE), not just a random sentence.
🏗️ Deploy in 5 Minutes
Ready to see the difference? We've published the core deployment templates on our new Memory Template repository.
Scale your intelligence without the complexity. The future is structured.
Best,
The FastBuilder.AI Team