Code Memory: How UpperSpace Reads Your Entire Codebase and Rebuilds the Architecture No One Documented
There's a trillion-dollar problem hiding in every software organization — from Fortune 500 enterprises to fast-scaling startups.
It's not a security breach. It's not a data leak. It's something far more insidious:
Nobody understands the code anymore.
Maybe the architect who designed the system retired in 2007. Maybe the founding engineers who understood the payment processing flow all moved to FAANG companies. Maybe the microservices grew organically across three teams and nobody kept track of how they wire together. What remains — whether it's 338 COBOL source files on a mainframe or 2,000 TypeScript modules across 40 repositories — is a system whose architecture lives nowhere except in the heads of people who may no longer be available.
This isn't a hypothetical scenario. This is the exact situation we encountered when we pointed UpperSpace's Code Memory engine at AWS CardDemo — Amazon's canonical COBOL mainframe reference application. And what our engine produced in minutes would have taken a team of consultants six months to deliver. But CardDemo is just one example. Code Memory works the same way on React frontends, Python microservices, Java monoliths, Go backends, and every codebase in between.
The Problem Isn't the Language. It's the Lost Architecture.
This problem isn't unique to legacy systems. It affects every codebase that has grown beyond a single team's comprehension — whether it's a 40-year-old mainframe application or a 3-year-old microservices platform.
Consider the COBOL example: any competent LLM can translate PERFORM VARYING into a Python for loop. The difficulty is that nobody knows why CBACT01C.cbl calls CBTRN01C.cbl, which then triggers COACTUP.bms to render an account activity screen that writes back to a VSAM file whose record structure is defined in COACTUP.CPY — which is shared with three other programs that all assume a specific field layout that will break catastrophically if anyone changes it.
Or consider a modern example: nobody documented why the OrderService calls InventoryService through a Kafka topic instead of a direct gRPC call, which then triggers a webhook to PaymentGateway that writes to a shared Postgres schema — which three other services also read from.
Same problem. Different era. The architecture was never written down. It lived in the heads of people who no longer work there.
Introducing Code Memory: Architecture That Reconstructs Itself
Code Memory is UpperSpace's ability to dynamically build a complete, high-definition architectural map of any codebase — from COBOL mainframes to modern microservices — without a single line of project-specific configuration, without pre-built schemas, and without any prior knowledge of the application.
We call this Zero-Knowledge Reverse Engineering.
Here's what makes it fundamentally different from every other code analysis tool on the market:
1. The Golden Mesh Catalog (CBFDAE)
Every codebase, regardless of language or era, can be decomposed into six universal architectural dimensions. UpperSpace reads the source code, parses its structure, and classifies every discoverable element into this six-layer ontology — the CBFDAE Golden Mesh Catalog:
C — Components
Components are the highest-level business modules in a system. They represent distinct domains of functionality that a business stakeholder would recognize — not arbitrary file groupings, but actual boundaries of business responsibility.
When UpperSpace read the AWS CardDemo codebase, it identified 16 components by analyzing naming conventions, call chains, and shared data dependencies across 338 files. Programs like CBACT01C.cbl, CBACT02C.cbl, and CBACT03C.cbl were automatically grouped into the AccountActivity component. CBCUS01C.cbl became CustomerMgmt. CBTRN01C.cbl, CBTRN02C.cbl, CBTRN03C.cbl became TransProcessing. Each component was classified by its architectural role: batch, service, integration, ui, or utility.
This is the dimension that traditional code analysis completely misses. Tools that parse individual files can tell you what a function does — but only CBFDAE tells you which business domain it belongs to and why it exists.
B — Blocks
Blocks are the processing units within each component — the major structural subdivisions that organize a component's internal work. In COBOL, these map to key program sections and processing divisions. In modern languages, they correspond to classes, modules, or service layers.
In CardDemo, UpperSpace identified blocks like AcctActivity_Block, CardFile_Block, CoreOperations_Block, and PaymentUpdate_Block. Each block is a self-contained processing unit that the parent component delegates to — for example, CustomerMgmt contains CustomerMgmt_Block, which encapsulates the create/update/query lifecycle for customer records.
Blocks are critical for migration planning. When decomposing a monolith, blocks define the natural fracture lines — the places where you can extract a microservice without breaking cross-component contracts.
F — Functions
Functions are the named procedures, paragraphs, and executable units that perform the actual computation. This is where the business logic lives — the PERFORM statements in COBOL, the def blocks in Python, the methods in Java.
UpperSpace extracted 178 functions from CardDemo, each mapped to its parent block and component. Key functions include account processing procedures (CBACT01C → account updates and postings), transaction handlers (CBTRN01C → transaction processing with integrity checks), and data exchange operations (CBEXPORT.cbl → aggregated data export triggering CA-7 job events).
The function catalog captures not just names, but relationships: which functions call which other functions, what data they consume and produce, and what events they trigger. This creates a navigable execution graph that reveals the actual runtime behavior of the system.
D — Data
Data items are the records, copybooks, file structures, database schemas, and shared definitions that carry information through the system. In mainframe applications, this dimension is especially critical because shared copybooks (*.CPY files) define record layouts that multiple programs depend on — change a field, and you risk breaking every program that includes that copybook.
UpperSpace mapped CardDemo's data architecture across multiple storage technologies: VSAM files for transactional records, fixed-length copybooks like COACTUP.CPY (activity records), COBIL00.CPY (billing data), and CBTRN*.cpy (transaction structures), plus DDL/DBD definitions for relational schema. Each data item was traced to its owning component and its access pattern — revealing which components share data and where hidden coupling exists.
This is the dimension that makes AI-generated code translations fail. An LLM can translate COBOL to Java line by line, but if it doesn't understand that COACTUP.CPY is shared by AccountActivity, PaymentUpdate, and StatementMgmt, the translated system will silently break data contracts.
A — Access
Access paths describe how components interact with data stores and external systems — the I/O patterns, protocols, and mechanisms that connect business logic to persistent state. In mainframe systems, access paths include SELECT/ASSIGN statements for file access, EXEC CICS SEND MAP for screen rendering, keyed VSAM reads/writes, and sequential file I/O.
UpperSpace identified 197+ access paths in CardDemo, classified by type: file-level access (COBOL programs reading/writing VSAM files), screen-level access (BMS screen definitions communicating with CICS terminals), batch-level access (JCL scripts invoking COBOL programs), and system-level access (assembler routines like COBDATFT.asm performing low-level date formatting and MVSWAIT.asm handling MVS synchronization).
Access paths are the system's nervous system. They reveal the actual I/O topology — which components are tightly coupled through shared file handles, which are loosely coupled through batch hand-offs, and which are completely isolated.
E — Events
Events are the triggers, signals, and control flows that drive the system's behavior over time. They capture when and why things happen — screen navigation events when a user transitions from sign-on (COSGN00.bms) to account management, batch trigger events when CA-7 schedules a nightly export job, file I/O events when a transaction write completes, and system call events when an assembler routine signals a wait condition.
UpperSpace cataloged 520+ events across CardDemo, grouped into four categories: screen navigation events (BMS interactions), batch trigger events (CA-7 and JCL scheduling), file I/O events (VSAM and sequential file operations), and system call events (assembler-to-COBOL signals). The event graph shows causal chains — for example, a user updating an account on COACTUP.bms triggers a screen navigation event, which invokes CBACT01C.cbl, which triggers file I/O events on the account VSAM file, which cascades into batch audit events logged for the nightly reconciliation job.
Events are the dimension that turns a static code map into a dynamic system model. Without events, you see structure. With events, you see behavior.
Together, these six dimensions form a complete, machine-readable representation of any application's inner architecture. When UpperSpace ran against the AWS CardDemo codebase, it produced:
Every node. Every link. Every dependency. Automatically extracted and classified.
2. Pure MCP Discovery — No Hardcoding, No Configuration
This is the part that consultants don't want you to hear.
UpperSpace's Code Memory engine connects to any codebase through the Model Context Protocol (MCP) — the same open standard that powers AI tool use across the industry. Through MCP, the engine dynamically:
- Inventories all source files — parsing file extensions, naming conventions, and directory structures to infer technology layers (
.cbl→ COBOL business logic,.bms→ BMS presentation screens,.jcl→ batch job control,.cpy→ shared data definitions) - Asks 10 architecture-discovery questions through the Golden Mesh Catalog intelligence layer — questions like "What are the main components of this application?", "How do components interact with each other?", and "What data stores does this application use?"
- Runs 22 targeted code search queries across both general architecture patterns and CBFDAE-specific patterns — searching for component boundaries, data flows, event triggers, security mechanisms, and integration interfaces
- Fetches the live CBFDAE topology graph — the component/block/function/data/access/event node-and-edge network that represents the actual structural relationships in the code
- Reads workspace documentation — extracting named components, function signatures, data item definitions, and access patterns from the project's own cataloged metadata
All of this happens automatically. The engine has zero knowledge of what CardDemo is, what COBOL looks like, or what CICS does. It discovers everything through dynamic protocol-level inquiry.
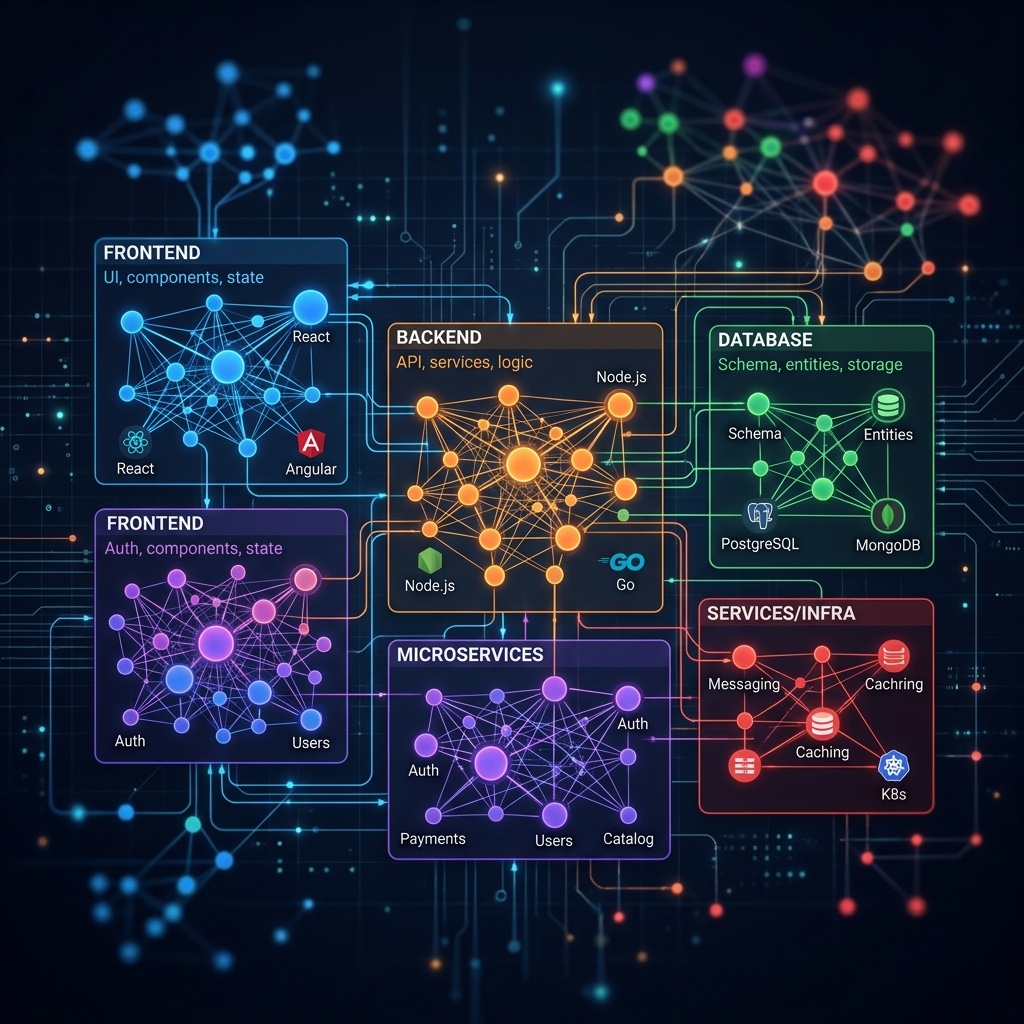
3. Interactive Force-Directed Architecture Visualization
Raw data isn't enough. Enterprise stakeholders — CTOs, architects, compliance officers, and project managers — need to see the architecture.
Code Memory produces a fully interactive, animated D3.js force-directed architecture dashboard that renders the CBFDAE topology as a living, breathing network graph:
What the CardDemo visualization reveals:
- 16 distinct component clusters — each rendered as a bounded box with its own color identity:
CustomerMgmt(green),TransProcessing(blue),PaymentUpdate(orange),CardInterface(purple),DataExchange(teal),AdminControl(cyan),StatementMgmt(coral), and more - 192 nodes representing components, blocks, and functions — sized by architectural significance (components are largest, functions are smallest)
- 938 directed links showing call chains, data flows, and dependency relationships — color-coded by type:
calls(blue),reads(green),writes(orange),triggers(purple) - Cross-component dependency chains that reveal the hidden wiring of the application
Stakeholders can zoom, pan, hover for tooltips, toggle labels, and animate data flows across the entire topology. This isn't a static diagram in a PowerPoint deck. It's a navigable map of architectural reality.
The AWS CardDemo Case Study: 338 Files to Full Architecture in Minutes
Let's walk through exactly what Code Memory produced when pointed at the AWS CardDemo application — Amazon Web Services' canonical reference implementation of a COBOL/CICS credit card management system.
The Application
CardDemo simulates a real-world mainframe credit card processing system. It includes:
- COBOL business programs (
CBACT01C.cbl,CBCUS01C.cbl,CBTRN01C.cbl) — processing account activities, customer management, and transactions - BMS screen definitions (
COACTUP.bms,COSGN00.bms,COUSR00.bms) — defining 3270 terminal user interfaces - Copybooks (
COACTUP.CPY,COBIL00.CPY,CBTRN*.cpy) — shared data definitions ensuring consistency across programs - JCL batch scripts (
CBEXPORT.jcl,CBIMPORT.jcl) — batch data export/import processing - Assembler routines (
COBDATFT.asm,MVSWAIT.asm) — low-level system integration - CA-7 scheduling (
CardDemo.ca7) — job orchestration and batch scheduling - DDL/DBD definitions — database schema and data model specifications
What Code Memory Discovered
Without any prior knowledge of CardDemo, the engine automatically identified and classified:
The Technology Stack Decomposition
┌────────────────────────────────────────────────────────────┐
│ Presentation Layer │ BMS screens (COACTUP, COSGN00, │
│ │ COUSR00, COADM01) │
├─────────────────────────┼──────────────────────────────────│
│ Business Logic Layer │ COBOL programs (CBACT01C, │
│ │ CBCUS01C, CBTRN01C, COACCT01) │
├─────────────────────────┼──────────────────────────────────│
│ Shared Data Layer │ Copybooks (COACTUP.CPY, │
│ │ COBIL00.CPY, CBTRN*.cpy) │
├─────────────────────────┼──────────────────────────────────│
│ Integration Layer │ ASM routines (COBDATFT, │
│ │ MVSWAIT), CA-7 scheduler │
├─────────────────────────┼──────────────────────────────────│
│ Batch Processing Layer │ JCL scripts (CBEXPORT, │
│ │ CBIMPORT), AWK utilities │
└────────────────────────────────────────────────────────────┘Cross-Component Dependency Map
The engine traced the complete execution flow across components, revealing chains that no static file-by-file analysis could detect:
↑ │
│ ├── notifies ──→ CustomerMgmt
│ │
└────── updates ──────────────┘
CoreOperations ── executes ──→ TransProcessing ── integrates ──→ DataExchange
│
└── finalizes ──→ FileClosure
CardFile ── routes ──→ CardInterface ── validates ──→ CardAudit
↑
CopybookAudit ── reviews ───┘
AdminControl ── controls ──→ CustomerMgmt ── updates ──→ TransProcessing
This is the hidden wiring of a 40-year-old mainframe application, fully reconstructed in minutes. No consultant interviews. No months of manual code reading. No tribal knowledge required.
Custom Document for a Software — Via MCP
The real power of Code Memory's CBFDAE topology is that it becomes a structured knowledge source that any LLM can consume via MCP. Once UpperSpace has built the deep architecture — the components, blocks, functions, data items, access paths, and events — that topology is exposed through the Model Context Protocol as a queryable graph.
This means any LLM-powered tool can connect to UpperSpace via MCP and generate any type of document from the architecture: migration plans, risk assessments, compliance reports, onboarding guides, test strategies, security audits, API specifications, or full system documentation. The CBFDAE topology provides the grounded, hallucination-resistant evidence layer — the LLM provides the synthesis and narrative.
For the CardDemo application, a single architecture extraction produced 195,000 characters of detailed, grounded documentation — every section populated with real component names, real function references, and real data item citations extracted directly from the codebase. But that's just one example. The topology is the foundation; the documents you build from it are limitless.
The Anti-Hallucination Layer
Here's something unique that no other AI code analysis tool does:
Code Memory includes a fabrication scrubber that actively verifies every file citation in any generated document against the actual file inventory. If the LLM hallucinates a file name that doesn't exist in the project — a common failure mode in AI-generated documentation — the scrubber automatically replaces it with "derived from project analysis" and logs the correction.
This isn't a post-processing filter. It's an architectural guarantee that every citation in the output is grounded in reality.
Why This Matters: Every Codebase, Every Language
This problem isn't limited to mainframes. According to McKinsey, enterprises worldwide spend $300 billion annually maintaining legacy systems alone — and modern codebases suffer from the same architectural amnesia as they scale beyond their original teams.
Whether you're modernizing a COBOL monolith, refactoring a sprawling Node.js microservices mesh, onboarding a new team to an inherited Python codebase, or auditing a Java enterprise application for compliance — the fundamental challenge is identical: nobody has a complete map of the architecture.
The current approach is broken:
| Current Approach | What Goes Wrong |
|---|---|
| Manual Reverse Engineering | Takes 6-18 months per application. Costs $2-10M per app. Depends on scarce expertise and tribal knowledge. |
| AI File-by-File Analysis | Produces syntactically correct but architecturally blind output. Misses cross-component dependencies. Generates 70% of the bugs that will haunt the refactored system. |
| Organic Documentation | Always out of date. Written by the people who don't need it, never read by the people who do. |
Code Memory eliminates the foundational bottleneck: the absence of architectural understanding.
With a complete CBFDAE topology map, teams can:
- Plan migrations and refactors by identifying component clusters and their dependency boundaries
- Estimate risk accurately by seeing which components are most interconnected (and therefore most dangerous to change first)
- Validate AI-generated code by checking whether changes preserve the existing topology
- Onboard new engineers instantly by giving them an interactive, navigable map instead of outdated wiki pages
The Technical Architecture of Code Memory
For the engineering-minded reader, here's how Code Memory works under the hood:
┌─────────────────────────┐
│ UpperSpace LocalApp │
│ (MCP Server @ :3500) │
└──────────┬──────────────┘
│ JSON-RPC 2.0
┌──────────▼──────────────┐
│ UpperSpace MCP Client │
│ (Protocol Layer) │
└──────────┬──────────────┘
│
┌────────────────┼────────────────┐
▼ ▼ ▼
┌─────────────┐ ┌──────────────┐ ┌──────────────┐
│ Evidence │ │ Architecture │ │ LLM Document │
│ Gatherer │ │ Generator │ │ Generator │
│ │ │ │ │ │
│ • File scan │ │ • Markdown │ │ • Any doc │
│ • GMC ask │ │ narrative │ │ via MCP │
│ • Code search│ │ • D3.js graph│ │ • Scrubber │
│ • Topology │ │ JSON data │ │ • Grounding │
│ • Workspace │ │ • HTML render│ │ │
└─────────────┘ └──────────────┘ └──────────────┘The system operates in three phases:
Phase 1: Evidence Gathering — The MCP client queries UpperSpace for the complete file inventory, CBFDAE topology graph, workspace documentation, and runs 10 architectural discovery questions plus 22 code search queries.
Phase 2: Architecture Synthesis — Two LLM passes transform the gathered evidence into (a) a detailed markdown architecture narrative with Mermaid diagrams and component inventories, and (b) a structured JSON graph for the D3.js force-directed visualization.
Phase 3: Document Generation — Any LLM can connect to the CBFDAE topology via MCP and generate documents of any type — migration plans, compliance reports, test strategies, or full system specifications. Every file citation is verified against the real inventory by the fabrication scrubber.
The Future: Current Mode and Future Delta
Code Memory doesn't just map what your code is. The UpperSpace platform supports two visualization modes:
- Current Mode — The living topology of your existing codebase as it stands today
- Future Delta — A planned architecture overlay showing what the modernized system will look like, with highlighted additions, removals, and transformations
This dual-horizon capability means Code Memory isn't a one-time analysis tool. It's a continuous architectural companion that tracks your codebase's evolution — whether you're modernizing a legacy mainframe, refactoring a modern monolith, or scaling a microservices platform — ensuring that every change preserves the structural integrity of the system.
Conclusion: Code Forgets. Code Memory Doesn't.
Enterprise codebases are the most complex human-built structures in existence. They contain more interconnections than any building, more logic paths than any highway network, and more hidden dependencies than any supply chain.
And until now, understanding them required the one resource that every enterprise is running out of: the people who built them.
Code Memory changes the equation. It makes the architecture visible, navigable, and permanent — regardless of whether the original architects are still available. It transforms months of manual reverse engineering into minutes of automated discovery. And it does it all without a single line of project-specific configuration.
The code may be old. But its architecture, once extracted, is timeless.
Try Code Memory on your own codebase at fastbuilder.ai/platform.
Code Memory is powered by UpperSpace, Fastbuilder.AI's enterprise code intelligence platform. The AWS CardDemo analysis referenced in this article was performed using UpperSpace's Code Memory engine connected to UpperSpace LocalApp via MCP. Full architecture visualizations and specifications are available on request.
AWS CardDemo is an open-source reference application provided by Amazon Web Services for mainframe modernization evaluation purposes.