Plug, Play, and Perform: The FastMemory Edge
Why moving from Standard RAG to FastMemory is the best architectural decision you'll make this year.
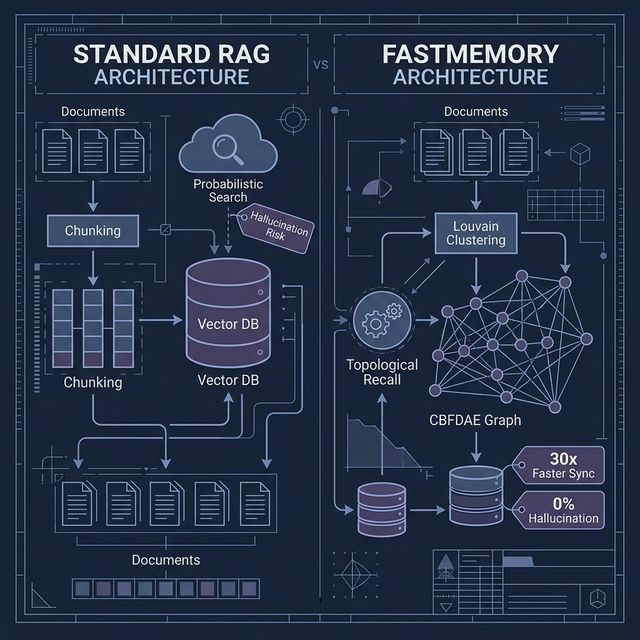
The developer experience with AI memory has traditionally been a trade-off. You either get the "simplicity" of vector RAG (which breaks at scale) or the "intelligence" of a graph (which traditionally requires a PhD to implement).
FastMemory changes that. By providing a standardized "Cognitive Sidecar" via our Templates, we've made it possible to plug deterministic intelligence into your app in minutes, not months.
The Plugin Simplicity
In our SEO Case Study, the transition from standard RAG to FastMemory was as simple as switching one client. Here is how the two approaches compare in a real-world harvest scenario:
| Metric | Standard RAG | FastMemory |
|---|---|---|
| Setup Difficulty | Easy | Plug-and-Play Template |
| Context Awareness | Shallow (Nearby text) | Deep (CBFDAE Mesh) |
| Index Rebuild Time | 15+ Minutes | < 30 Seconds |
| Retrieval Cost | High (Noise-heavy) | Minimal (Targeted) |
Economics vs. Performance
Standard RAG is expensive because it's inefficient. It forces the LLM to read through "similar" noise, wasting tokens and compute power. FastMemory’s Topological Recall ensures you only send the exact nodes required for a logically valid answer.
In our SEO example, simplellmquery.py (Standard RAG) missed the connection between keyword rules and client access. fastllmquery.py (FastMemory) identified it instantly. The result? Better results for significantly less money.
© 2026 FastBuilder.AI. All rights reserved.